Overfitting
Notes
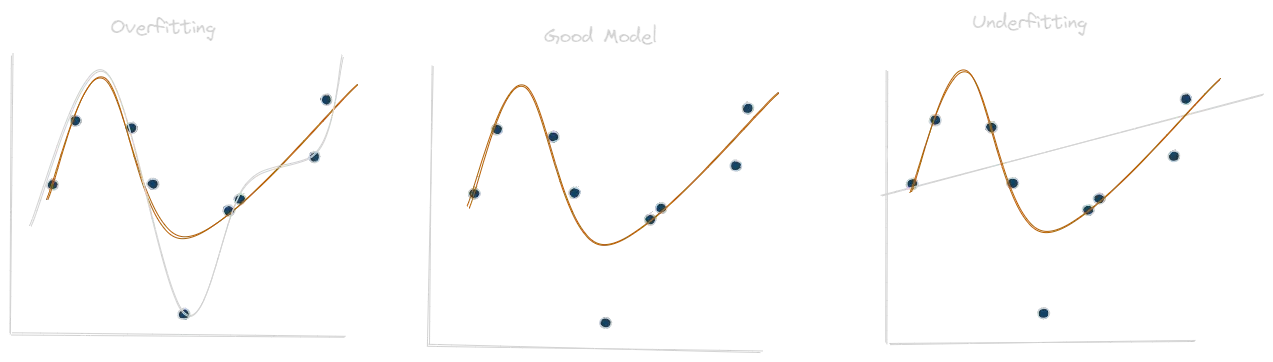
Overfitting is when we added complexity into our model such that it will have a better match to our train data, but this complexity only lowers our accuracy when the model encounters new data. Meaning that the model has overfitted it weights based on noise that should be ignored.
Overfitting is opposed to underfitting, which is the case where our model is too simplistic such that it didn't capture the causal relationship between the variables.
A good measure of over/under fitting is to split our data to train and test. An overfitted model will preform well on the train data, but will fail on the test, An underfitted model will fail both the train and test data and a good model will preform will in both.
Overfitting is not limited to machine learning but also in real life. For example the Goodhart’s Law could be a result of overfitting. When we focus on the measure we fail to succeed in implementing our knowledge. For example, when we study for a test by repeating previous test questions, while failing when we would encounter new sets of questions.
An answer to that is similar, we need to have pop quizzes that will test our knowledge in new situations and compare to our success on the "well known test".
Second of all, we need to notice the trend, and give weights to the history, and not change our opinion with every new piece of information.
Visual
Overview
🔼Topic:: Data Science (Map) ◀Origin:: Algorithms to Live By (book)